




Description
This n8n template showcases how to harness the power of Google Gemini 2.0's prompt-based Bounding Box detection — unlocking a smarter way to detect objects in images using natural language.
Instead of pre-trained object classes, you can now ask things like:
🔍 “Draw a box around adults holding children”
🚗 “Detect all improperly parked cars”
🐰 “Find all bunnies in this image”
It’s contextual, flexible, and requires zero model training.
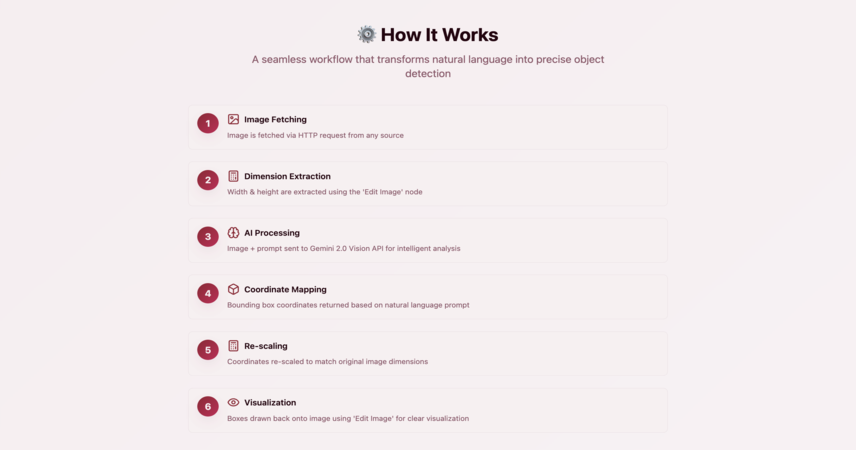
⚙️ How It Works
🖼️ Image is fetched via HTTP request
📏 Width & height are extracted using the “Edit Image” node
🧠 Image + prompt sent to Gemini 2.0 Vision API
🧮 Bounding box coordinates returned based on prompt
📐 Coordinates re-scaled to match original image size
🖊️ Boxes drawn back onto image using “Edit Image” for visualization
💡 Use Case Ideas
🛡️ Smart content moderation (e.g. detect @s, alcohol, etc.)
🛒 Retail shelf monitoring (e.g. highlight missing products)
📸 Security footage analysis (e.g. detect crowd clusters)
🖥️ UX feedback review (e.g. locate logos/UI issues in screenshots)
🔧 Requirements
✅ Google Gemini 2.0 with Vision API access
✅ Any image input (via URL or upload)
✅ n8n instance with HTTP + Edit Image nodes
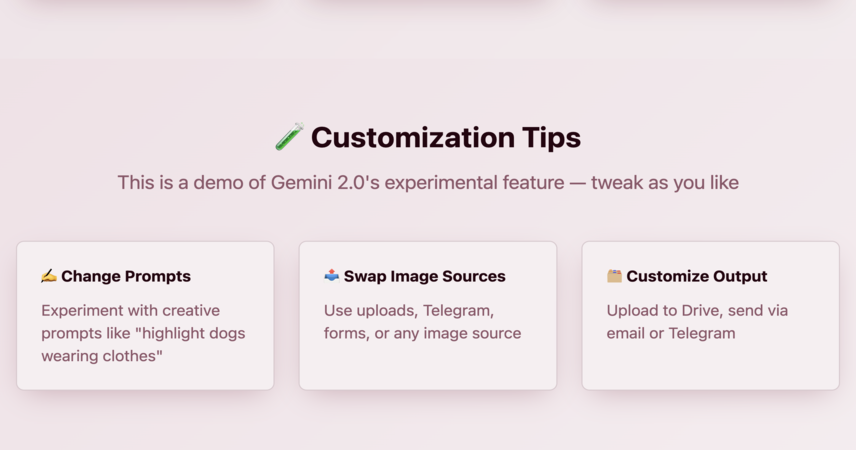
🧪 Customization Tips
This is a demo of Gemini 2.0's experimental feature — tweak as you like:
✍️ Change prompts (e.g. “highlight dogs wearing clothes”)
📤 Swap image sources (uploads, Telegram, forms, etc.)
🗂️ Customize output (upload to Drive, send on email/Telegram)
⚠️ Note: Production use not advised until Gemini 2.0 Vision becomes stable
Project Link:-[https://preview--gemini-vision-prompt-boxes.lovable.app/]






 Visit Main Gignaati Website
Visit Main Gignaati Website Learn with Gignaati Academy
Learn with Gignaati Academy Explore Workbench
Explore Workbench Partner with Us
Partner with Us Invisible Enterprises – Buy on Amazon
Invisible Enterprises – Buy on Amazon Terms & Conditions
Terms & Conditions Privacy Policy
Privacy Policy