



Description
Still relying on cloud APIs for every AI interaction?
This smart workflow lets you run local Large Language Models (LLMs) right inside your n8n automation — giving you privacy, speed, and full control over your data.
Whether you're building an offline chatbot, a secure assistant, or just exploring edge deployments, this flow gives you a plug-and-play chat interface powered by your own local LLM instance.
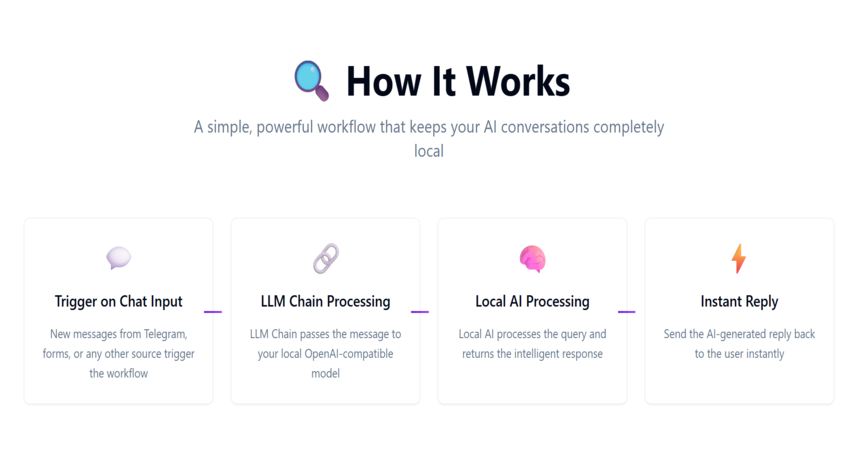
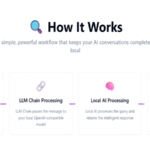
🔍 How It Works:
✅ Trigger on new chat input (via Telegram, form, or any other source)
✅ LLM Chain passes the message to your local OpenAI-compatible model
✅ Local AI processes the query and returns the response
✅ Send the reply back to the user instantly
⚙️ Why Use This Local LLM Flow?
🔒 Total Privacy – No external API calls, your data stays local
⚡ Faster Response Times – No latency from remote servers
💸 No Token Costs – Run open models like Mistral, LLaMA, or GPT-J locally
🧱 Simple & Modular – Easy to plug into any n8n chat flow
🖥️ Edge Ready – Works with OpenRouter, LM Studio, Ollama, etc.
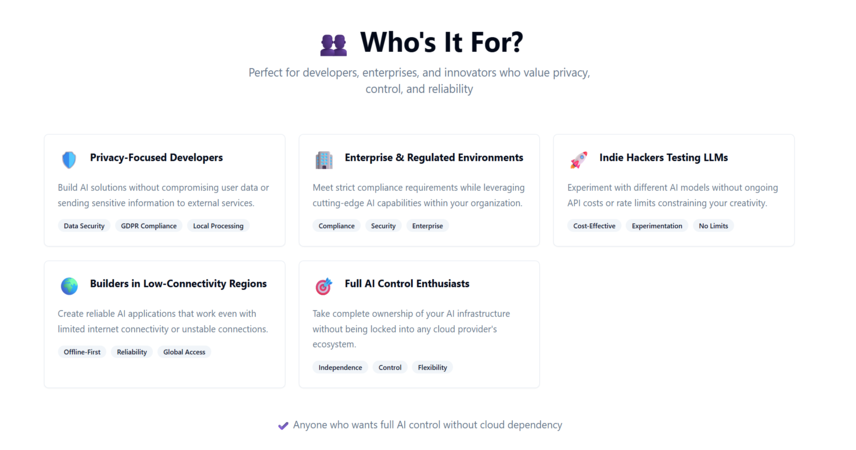
👥 Who’s It For?
✔️ Privacy-Focused Developers
✔️ Enterprise & Regulated Environments
✔️ Indie Hackers Testing LLMs
✔️ Builders in Low-Connectivity Regions
✔️ Anyone who wants full AI control without cloud dependency
🔌 Works Seamlessly With:
-
n8n Chat Trigger (Telegram, webchat, WhatsApp, etc.)
-
OpenAI-Compatible Local Models (via API)
-
LLM Chain Node (for prompt handling)
-
Optional Reply Nodes (email, messaging, logging, etc.)
💡 Build smarter bots with zero cloud dependency.
Run your own GPT-level chat assistant — right from your laptop or server.
🚀 Ready to take AI offline? Start chatting locally today.
Project Link - https://preview--local-llm-chat-flow.lovable.app/







 Visit Main Gignaati Website
Visit Main Gignaati Website Learn with Gignaati Academy
Learn with Gignaati Academy Explore Workbench
Explore Workbench Partner with Us
Partner with Us Invisible Enterprises – Buy on Amazon
Invisible Enterprises – Buy on Amazon Terms & Conditions
Terms & Conditions Privacy Policy
Privacy Policy