





Description
Are you manually switching between models and wasting hours trying to compare LLM performance on your tasks?
Let my AI-powered Testing & Tracker workflow do the hard work — locally and across multiple models!
This intelligent setup uses your local compute (Ollama or LM Studio) and APIs like OpenAI, Mistral, or Together AI to run structured prompts across multiple LLMs — and logs outputs, costs, and speed in real-time dashboards.
🔹 How It Works:
✅ Choose your prompt or upload a test set
✅ Select which local/API LLMs to run (Ollama, OpenAI, Mistral, etc.)
✅ Workflow sends the same prompt to each model
✅ Captures the response, latency, token usage, and cost
✅ Logs everything to Airtable / Supabase / Sheets for easy comparison
✅ Optional scoring: Rate responses manually or let AI evaluate them
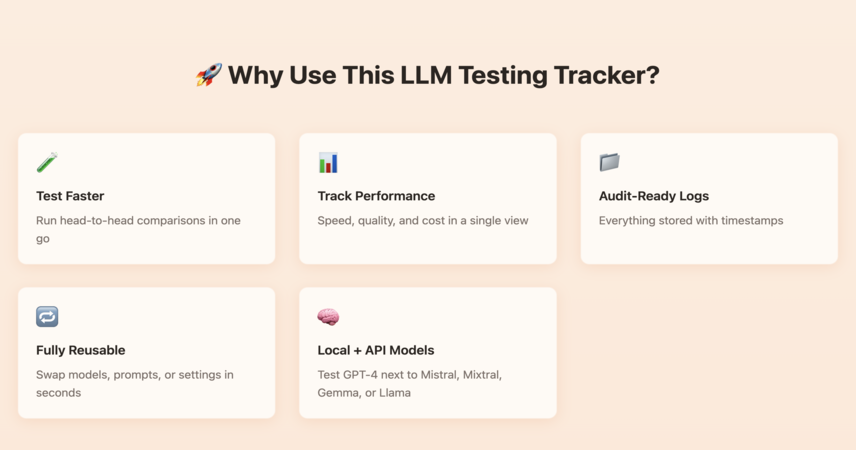
🚀 Why Use This LLM Testing Tracker?
🧪 Test Faster – Run head-to-head comparisons in one go
📊 Track Performance – Speed, quality, and cost in a single view
📁 Audit-Ready Logs – Everything stored with timestamps
🔁 Fully Reusable – Swap models, prompts, or settings in seconds
🧠 Local + API Models – Test GPT-4 next to Mistral, Mixtral, Gemma, or Llama
👥 Who Is This For?
✔️ AI Engineers & Prompt Designers
✔️ Researchers & LLM Evaluators
✔️ App Builders Testing Model Fit
✔️ AI Product Teams doing AB testing
✔️ Anyone tired of guessing which model works best
📦 Integrations Available:
Ollama, OpenAI, LM Studio, Mistral API, Together AI, Supabase, Airtable, Google Sheets, Telegram, Custom Forms







 Visit Main Gignaati Website
Visit Main Gignaati Website Learn with Gignaati Academy
Learn with Gignaati Academy Explore Workbench
Explore Workbench Partner with Us
Partner with Us Invisible Enterprises – Buy on Amazon
Invisible Enterprises – Buy on Amazon Terms & Conditions
Terms & Conditions Privacy Policy
Privacy Policy