

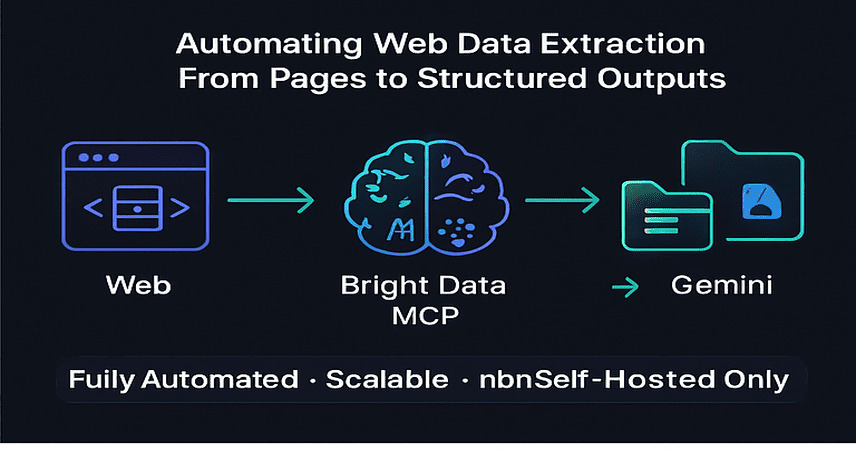





Description
This AI-powered workflow leverages Bright Data’s MCP Server and Google Gemini to automate intelligent, large-scale web data extraction and transformation. Built for n8n self-hosted with a custom community node, it turns raw HTML into structured, enriched output — ready for reporting, AI pipelines, or automation workflows.
👥 Who Is This For
📊 Data Analysts
To generate structured, enriched datasets for analysis and dashboards
📈 Marketing Researchers
To gather real-time insights from dynamic online sources
🧪 Product Managers
To monitor features, pricing, and positioning across competitors
🤖 AI Developers
To feed clean web data into ML/NLP pipelines
🚀 Growth Hackers
To extract campaign-ready, high-quality market data at scale
❗️What Problem Does It Solve
⏳ Manual web scraping is slow and brittle
🧹 Cleaning raw HTML is time-intensive
📉 Hard to scale data extraction workflows
🧩 Data pipelines often break without structured input
💡 The Solution
This workflow automates web scraping and AI-driven content processing with minimal setup:
🔗 Accepts target URL(s) for scraping
🛠️ Uses Bright Data MCP Server to unlock and extract HTML/Markdown
🧠 Transforms content using Google Gemini for insights and summaries
📤 Saves output to disk and sends it via webhook
⚙️ How It Works – The Process
📨 Trigger Input
Manually triggered or configurable for automation
🔗 URL Input
Specify one or more URLs to scrape
🧱 Web Scraping (Bright Data MCP)
Scrapes target site using MCP Server, returns HTML and Markdown
🧾 Data Storage & Delivery
Saves results to local disk and pushes via Webhook (e.g. Slack, Notion, etc.)





 Visit Main Gignaati Website
Visit Main Gignaati Website Learn with Gignaati Academy
Learn with Gignaati Academy Explore Workbench
Explore Workbench Partner with Us
Partner with Us Invisible Enterprises – Buy on Amazon
Invisible Enterprises – Buy on Amazon Terms & Conditions
Terms & Conditions Privacy Policy
Privacy Policy